
Data Transformation Benchmark
Can LLMs reliably transform data between SaaS APIs?

Data transformations are the heart of any integration. A good integration developer builds a mental model for each system and create pipelines that account for data in all of its glorious messiness.
We built an evaluation suite that tests LLMs on their ability to assume the integration developer role. We constructed 20 real-world data transformation scenarios spanning popular marketing platforms like Shopify, Salesforce, HubSpot, Braze, Klaviyo, and more. Each scenario requires the model to read source and target JSON schemas, interpret natural-language mapping instructions, and produce a working transformation that passes strict schema validation.
Best models for data integration mapping
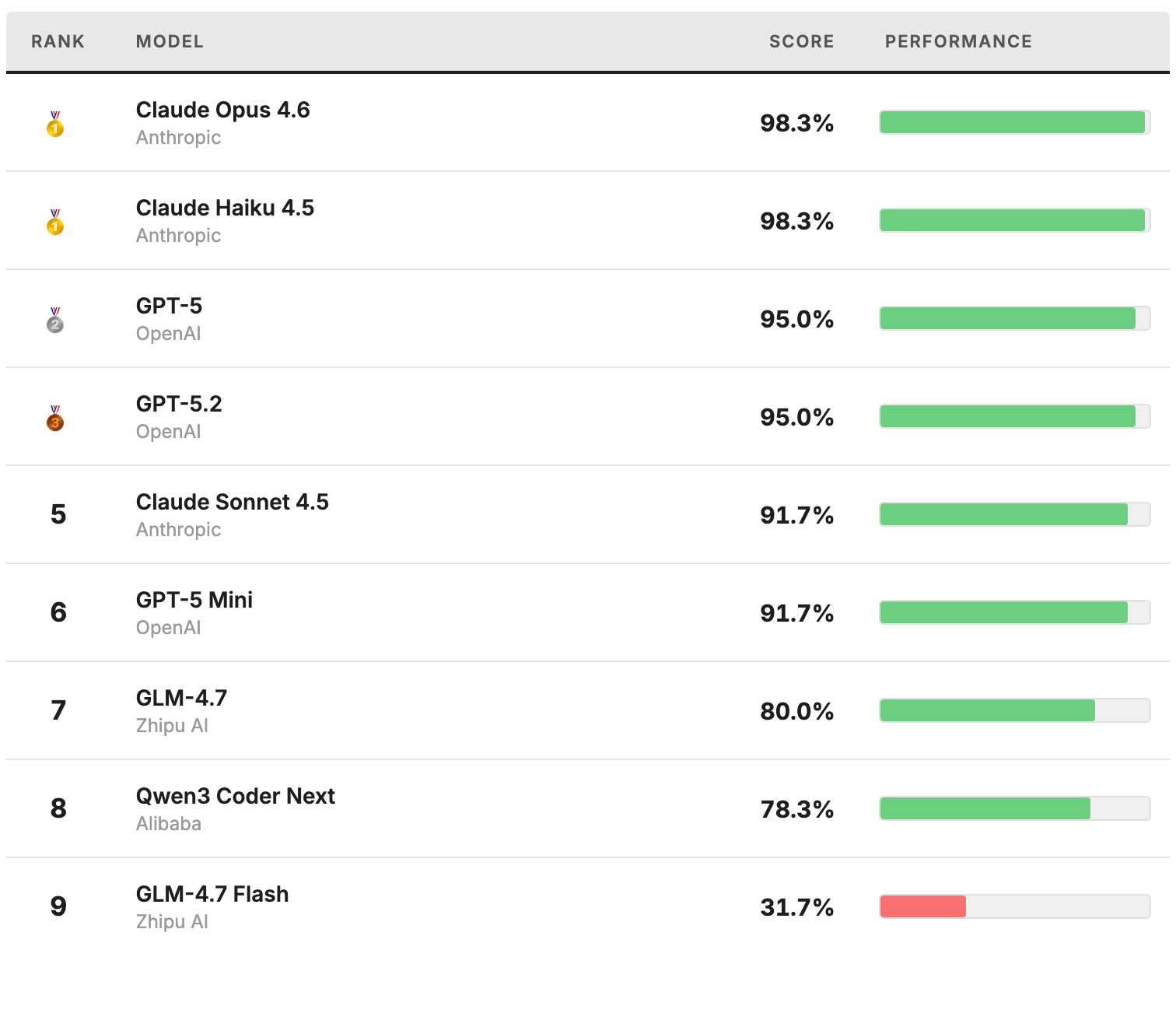
You don’t always need the biggest model
With accurate schemas, frontier LLMs reliably generate correct transformation code, even across complex, deeply nested structures. Surprisingly, Claude Haiku 4.5 scored a 98.3% which matched the performance of the larger and more capable Opus 4.6 model. This indicates that the data transformation tasks are unlikely to benefit from further model improvements. As model capabilities continue to improve, reaching for the highest intelligence option will be increasingly unnecessary. Evals are critical for identifying the right level of capability for a given task.
Evaluation structure
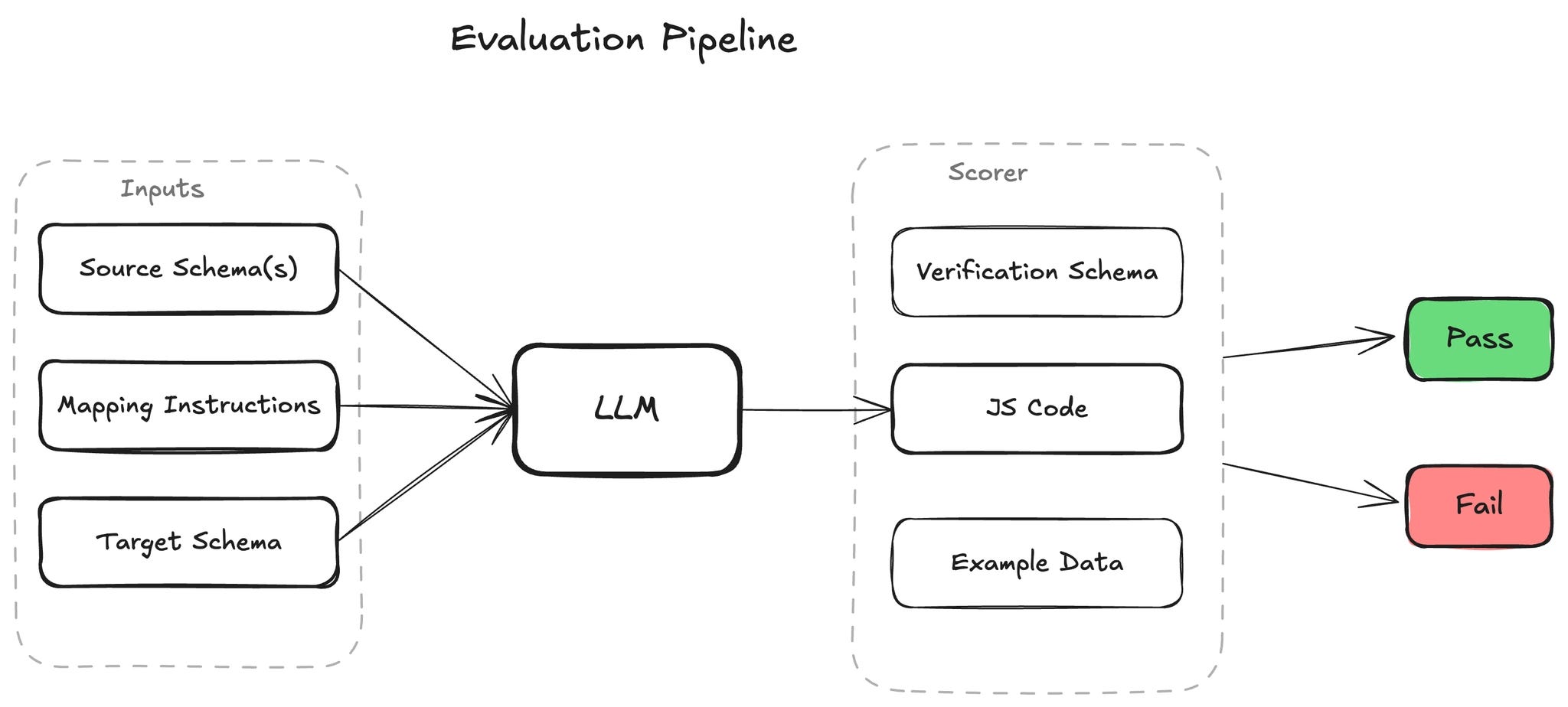
The evaluation measures whether an LLM can produce a JavaScript function that correctly transforms a set of SaaS webhook payload and API response objects into a desired SaaS API request body.
For each completion, the LLM is provided:
Source schemas — JSON schemas for one or more integration resources, such as a Shopify customer created webhook payload or a Contact object from the Salesforce API
Target schema — The JSON schema for an integration resource to which the output must conform (e.g. a Braze update user API request body)
Natural-language instructions — Plain english instructions describing which fields to map. The instructions are intentionally terse and do not use precise field names in order to reflect real-world user prompts.
Common data mapping guidelines — A checklist of things to ensure before responding to the user (e.g. type conversions, date-time formatting, null handling, etc…)
The response is scored by executing the generated JavaScript function against real example data from the source API or webhook. A binary pass / fail score is assigned based on whether the resulting object passes JSON validation for the target schema. To measure reliability rather than single-pass results, each test case is evaluated 3 times for a total of 60 test case evaluations per model.
Test case design
The test cases are drawn from real customer integration scenarios and span three difficulty levels:
Low (7 tests): Single-source, straightforward field mapping. Tests basic schema comprehension and field correspondence.
Medium (7 tests): Multi-source merging, date formatting, type conversion, array construction, and distractor filtering (irrelevant sources included in the input).
High (6 tests): Complex nested structures, multi-source cross-referencing, deep flattening, dual-target outputs, and date/format transformations.
Future plans
This benchmark is a starting point, and there are many planned improvements including:
More models — Expand to include the Gemini model family and GLM-5
More test cases — Add scenarios covering additional API platforms and edge cases like malformed data
More inputs — Execute the LLM-generated data transformation against more than one example input
We’re also exploring whether a purpose-built DSL for JSON transformations can match the performance of general purpose programming languages while providing better static analysis capabilities.
The full evaluation suite and results are available on GitHub.